

Latar Belakang LLM
Pengembangan model bahasa telah menjadi landasan kemajuan dalam bidang kecerdasan buatan. Pada awalnya, model-model ini sangat sederhana, berfokus pada prediksi dan analisis teks dasar berdasarkan algoritma berbasis aturan. Namun, pengenalan pembelajaran mesin dan, lebih khusus lagi, teknik pembelajaran mendalam, merevolusi kemampuan mereka. Munculnya arsitektur transformator pada tahun 2017, melalui makalah penting “Attention Is All You Need” oleh Vaswani dkk., menandai lompatan yang signifikan. Arsitektur ini memungkinkan model untuk memproses kata-kata dalam hubungannya dengan semua kata lain dalam sebuah kalimat, yang sangat meningkatkan pemahaman dan pembuatan teks yang kompleks.
Model-model tertutup, seperti GPT (Generative Pretrained Transformer) dari OpenAI, memamerkan potensi kemajuan ini, memberikan kinerja yang belum pernah ada sebelumnya dalam tugas-tugas seperti penyelesaian teks, penerjemahan, dan percakapan. Namun, sifat eksklusif dari model-model tersebut membatasi akses ke beberapa orang tertentu, sehingga menimbulkan kekhawatiran tentang pemerataan manfaat AI.
Tanggapan dari komunitas AI adalah sebuah langkah yang menentukan menuju inisiatif sumber terbuka. Upaya ini bukan hanya tentang menciptakan alternatif tetapi juga tentang menumbuhkan budaya transparansi, kolaborasi, dan inovasi. LLM open-source dibangun berdasarkan prinsip bahwa pengembangan kolektif dapat mempercepat kemajuan, mengurangi risiko bias dan ketidakadilan, serta mendemokratisasi akses ke teknologi.
Munculnya LLM Open Source
Munculnya LLM open-source dapat dikaitkan dengan beberapa faktor utama. Yang pertama adalah meningkatnya pengakuan atas pembatasan dan masalah etika yang terkait dengan model proprietary. Isu-isu seperti privasi data, transparansi model, dan monopoli teknologi AI oleh beberapa perusahaan telah mendorong pencarian alternatif yang lebih inklusif dan mudah diakses.
Faktor penting lainnya adalah kemajuan perangkat lunak dan perangkat keras open-source, yang telah menurunkan penghalang untuk mengembangkan dan melatih model yang kompleks. Ketersediaan dataset open-source berkualitas tinggi, bersama dengan peningkatan sumber daya komputasi, telah memungkinkan para peneliti independen dan organisasi yang lebih kecil untuk berkontribusi pada bidang LLM.
Proyek-proyek yang digerakkan oleh komunitas telah menjadi inti dari gerakan ini. Platform seperti GitHub dan Hugging Face telah menjadi pusat utama untuk kolaborasi, yang memungkinkan para pengembang dan peneliti dari seluruh dunia untuk berbagi pekerjaan mereka, membangun pencapaian orang lain, dan mendorong batas-batas apa yang mungkin dilakukan dengan LLM. Upaya kolektif ini telah menghasilkan pengembangan model yang tidak hanya menyaingi, tetapi dalam beberapa kasus, melampaui kemampuan dari model-model milik mereka.
Model-Model Open-Source Terkemuka
Lanskap LLM open-source sangat kaya dan beragam, dengan masing-masing model membawa kekuatannya sendiri-sendiri. Dua model yang paling terkenal dalam bidang ini adalah LLaMA dan Mistral, tetapi mereka tidak sendirian. Proyek-proyek lain, seperti GPT-Neo dan GPT-J dari EleutherAI, juga memberikan kontribusi yang signifikan.
- LLaMA: Dikembangkan dengan tujuan untuk menyediakan model bahasa yang berkualitas tinggi dan serbaguna, LLaMA menonjol karena efisiensi dan kemampuan beradaptasi. LLaMA menawarkan kinerja yang kompetitif di berbagai tugas, mulai dari pemahaman bahasa natural hingga pembuatan konten, menjadikannya sumber daya yang berharga bagi para peneliti dan pengembang.
- Mistral: Membedakan dirinya dengan kinerjanya dan keterbukaan proses pengembangannya. Mistral telah dibandingkan dengan model-model yang sudah ada dan terbukti menawarkan hasil yang sebanding, bahkan lebih unggul, dalam skenario-skenario tertentu. Model ini mencontohkan potensi pengembangan sumber terbuka untuk mencapai hasil mutakhir dalam AI.
- Model Lainnya: GPT-Neo dan GPT-J adalah contoh upaya yang digerakkan oleh komunitas untuk mereplikasi dan memperluas kemampuan model transformator skala besar. Model-model ini sangat penting dalam menunjukkan bahwa kolaborasi terbuka dapat menghasilkan tool yang kuat dan dapat diakses oleh khalayak luas.
Pengujian dan Peringkat
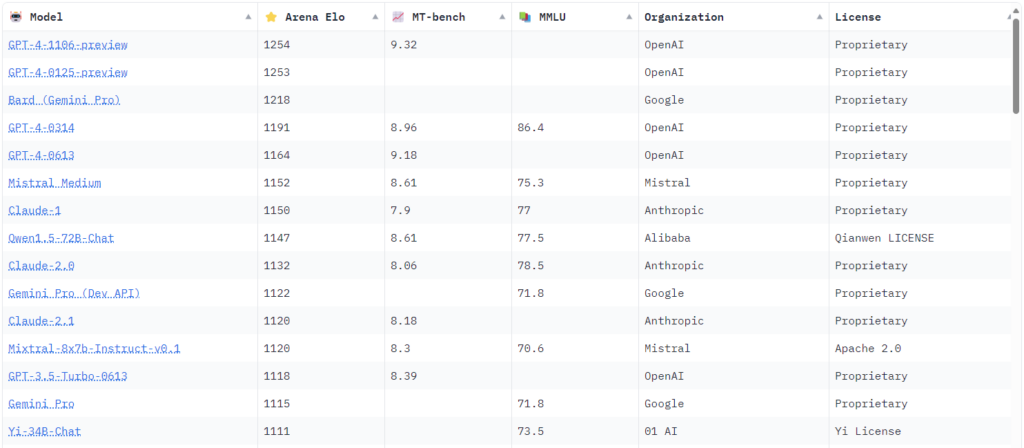
Untuk menilai kinerja LLM open-source secara objektif, sangat penting untuk merujuk pada standar acuan. “Papan Peringkat Chatbot Arena” di Hugging Face berfungsi sebagai platform standar acuan yang komprehensif, membandingkan model seperti Mistral dengan model-model proprietary.
- Metriks Kinerja: Peringkat ini mengevaluasi model berdasarkan berbagai metrik, termasuk akurasi, koherensi, dan waktu respons. Metriks ini memberikan pandangan menyeluruh tentang kemampuan model, mulai dari kemampuannya untuk memahami dan menghasilkan respons yang relevan hingga efisiensinya dalam memproses permintaan.
- Pencapaian Mistral: Dalam arena kompetitif ini, Mistral telah menunjukkan kinerja yang luar biasa, menyamai atau bahkan melampaui model-model yang sudah ada sebelumnya dalam beberapa metrik tertentu. Ini adalah bukti kualitas dan potensi model open-source untuk berkontribusi secara signifikan pada bidang AI.
- Implikasi: Keberhasilan Mistral dan model open-source lainnya dalam pengujian ini menyoroti kelayakan pendekatan kolaboratif yang digerakkan oleh komunitas untuk mengembangkan teknologi AI berkinerja tinggi. Hal ini menantang anggapan bahwa hanya model proprietary yang dapat memimpin dalam hal inovasi dan efektivitas.
Dengan memeriksa model-model open-source utama dan kinerjanya pada acuan yang telah diakui, kami mendapatkan wawasan tentang lanskap penelitian dan pengembangan AI yang dinamis dan berkembang pesat. Pencapaian model-model ini tidak hanya menggarisbawahi nilai inisiatif open-source dalam mempromosikan inovasi dan aksesibilitas dalam AI, tetapi juga mengisyaratkan masa depan di mana upaya kolaboratif terus menciptakan terobosan baru dalam teknologi.
Tantangan dan Keterbatasan
Terlepas dari kemajuan yang menjanjikan dari LLM open-source, beberapa tantangan dan keterbatasan masih ada, yang berdampak pada pengembangan dan adopsi secara luas.
- Tantangan Teknis: LLM open-source sering kali membutuhkan data dan sumber daya komputasi dalam jumlah besar untuk pelatihan, sehingga kurang dapat diakses oleh individu dan organisasi dengan sumber daya yang terbatas. Selain itu, mempertahankan kinerja model sambil memastikan privasi dan keamanan tetap menjadi tantangan yang kompleks.
- Pertimbangan Etis: Isu-isu seperti bias, keadilan, dan penggunaan etis menjadi lebih besar dalam proyek open-source karena sifatnya yang publik dan memiliki aksesibilitas yang luas. Memastikan bahwa model-model ini tidak menyebarkan bias atau informasi yang salah dan berbahaya membutuhkan upaya dan kewaspadaan yang berkesinambungan dari komunitas.
- Keberlanjutan: Ketergantungan pada kontribusi sukarelawan dan pendanaan publik dapat menimbulkan tantangan keberlanjutan untuk proyek LLM open-source. Memastikan dukungan dan pengembangan jangka panjang membutuhkan model yang menyeimbangkan antara keterbukaan dan viabilitas finansial.
Komuinitas dan Kolaborasi
Keberhasilan LLM open-source sangat bergantung pada kekuatan dan keterlibatan komunitas. Kolaborasi lintas batas dan disiplin ilmu telah menjadi kekuatan pendorong di balik kemajuan pesat model-model ini.
- Platform untuk Kolaborasi: Platform online seperti GitHub dan Hugging Face telah menjadi pusat untuk mendorong kolaborasi, memungkinkan untuk berbagi kode, kumpulan data, dan temuan penelitian. Platform-platform ini juga memfasilitasi diskusi dan umpan balik, yang sangat penting untuk perbaikan berulang.
- Kontribusi dari Berbagai Latar Belakang: Model open-source mendorong partisipasi dari berbagai kontributor, termasuk peneliti, penggemar, dan profesional industri. Keragaman ini membawa banyak perspektif dan keahlian, mendorong inovasi dan mengatasi tantangan dari berbagai sudut.
Prospek Masa Depan
Masa depan LLM open-source terlihat menjanjikan, dengan beberapa tren yang menunjukkan pertumbuhan dan dampak yang berkelanjutan.
- Kemajuan Teknologi: Penelitian dan pengembangan yang sedang berlangsung diharapkan dapat mengatasi keterbatasan yang ada saat ini, sehingga menghasilkan model yang lebih efisien, akurat, dan etis. Teknik seperti few-shot learning dan model distillation menawarkan jalan untuk mengurangi kebutuhan sumber daya dan meningkatkan aksesibilitas.
- Adopsi dan Dampak yang Lebih Luas: Ketika model-model ini menjadi lebih mampu dan ramah pengguna, pengadopsiannya di berbagai industri cenderung meningkat, mendorong inovasi di berbagai bidang mulai dari perawatan kesehatan, pendidikan, hingga hiburan.
- Pertumbuhan dan Tata Kelola Komunitas: Komunitas open-source kemungkinan besar akan berkembang, membawa lebih banyak kontributor dan pemangku kepentingan. Pertumbuhan ini akan membutuhkan pengembangan model tata kelola yang memastikan kemajuan teknologi LLM yang etis dan berkelanjutan.
Kesimpulan
LLM open-source mewakili perubahan signifikan dalam lanskap AI, mendemokratisasi akses terhadap teknologi mutakhir dan menumbuhkan budaya kolaborasi dan inovasi. Meskipun tantangannya masih ada, pendekatan berbasis komunitas telah terbukti menjadi model yang ampuh untuk memajukan penelitian dan pengembangan AI. Masa depan LLM open-source bukan hanya tentang terobosan teknologi tetapi juga tentang membangun ekosistem AI yang inklusif, etis, dan berkelanjutan.




